Given that we now have the lo interface available, would it be a good idea to change this:
/ip firewall filter add chain=input action=accept dst-address=127.0.0.1 comment="defconf: accept to local loopback (for CAPsMAN)"
to this?
/ip firewall filter add chain=input action=accept in-interface=lo comment="defconf: accept to local loopback (for CAPsMAN)"
Especially since RouterOS sometimes can use other addresses for loopback, for example from 192.168.1.1 to 192.168.1.1, which comes in through the lo interface but the default rule will not let it through (other rules might, but they can be different depending on how someone wants to have their firewall configured).
Looks like the first version is still in the default configuration. Is there a reason for it, or did they just forget to update it?
There will be no pratical difference, since 127.0.0.1 will always work, just as lo. There is also no real performance difference with the loads you can expect in such a setup.
I recall The Dude having a problem with that, where the router tried to connect to itself using different addresses than 127.0.0.1, though that was before the lo interface existed and I don’t have The Dude currently installed to test how it works now. However, I noticed that this happens in prerouting (which the filter rule has nothing to do with, but I also had a rule in Raw to allow loopback from 127.0.0.1, and changed it to allow from lo after noticing it):
prerouting: in:lo out:(unknown 0), connection-state:related proto ICMP (type 3, code 1), 192.168.100.1->192.168.100.1, len 82
In practice lo interface will only have address 127.0.0.1 in vast majority of times … many people talk about “using loopback” when device connects itself to any of own addresses … regardless the interface involved. E.g. default has 192.168.88.1 set on bridge and there will still be people talking about loopback when talking about ROS talking to itself using 192.168.88.1 .
Sometimes people (ab)used a bridge without ports as “loopback” and assigned IP addresses to it. This is a more likely use case for “actual” lo interface. And in this case using in-interface=lo instead of dst-address=127.0.0.1 is perhaps even counter-productive.
I’m not sure I understood you correctly, are you saying that this should come in through the interface the 192.168.100.1 address is set on, instead of lo? Then why does it come in through lo?
prerouting: in:lo out:(unknown 0), connection-state:related proto ICMP (type 3, code 1), 192.168.100.1->192.168.100.1, len 82
Also, what would be the “correct” way to do this? Manually setting a separate firewall rule for each interface to allow the router back to itself on it? What if I have some interfaces from which forward is allowed but input isn’t, but I still want the router to be able to communicate back to itself on them?
You speak in riddles.
What is the requirement in traffic flow for.
a. user
b. device
Allow the router back to itself means nothing to me.
Are you saying the admin needs to do something, a user needs to do something, explain in terms of required traffic flow.
Unless of course, you have an AI mikrotik and you are serving a new master.
So you’re saying that 192.168.100.1/24 is set on bridge interface. Then some ROS process starts connection towards 192.168.100.1 and firewall shows the image you posted above (i.e. interface used lo?). If so, then this is IMO a bug … probably in firewall logs/stats handling.
In linux kernel connections to own IP address are a bit tricky to grasp. That’s because such connection is entirely handled by IP stack … which means no L2 devices are involved. And due to that it might be hard to “detect” either ingress or egress interface (which is L2 entity, supporting a particular L3 address). A side effect of this is that speed tests, which are entirely internal to same host (e.g. iperf between two instances of iperf run on same host … bound to different TCP/UDP ports and same IP address which is not 127.0.0.1), will show throughputs higher than what physical interface allows (e.g. 1 Gbps) …
Right … I meant “physical interface” … and lo obviously doesn’t have any physical interface underlying. How about running btest against ether1 (or any other interface which exists in physical form and bears IP setup)?
I looked a bit more into what causes that log entry to appear. The 192.168.100.1 address is set on a WireGuard interface with a few peers that aren’t always connected. Netwatch is set up to ping the peers every few minutes to log whenever one of them disconnects. The log entry comes from one of the Raw firewall drop rules that I set logging on, probably for the purpose of testing something else. Looks like when Netwatch tries to ping one of the peers that isn’t online at the time, the router (that both the WireGuard interface and Netwatch is set up on) sends a “Destination unreachable: Host unreachable” response to itself using the WireGuard interface’s address both as source and destination, which apparently comes in through lo instead of the WireGuard interface.
So now I’m confused. Should the router always use 127.0.0.1 when responding to itself in this way (and if so, then why doesn’t it do that?), should the router not do something like that, or should it use the WireGuard interface for that?
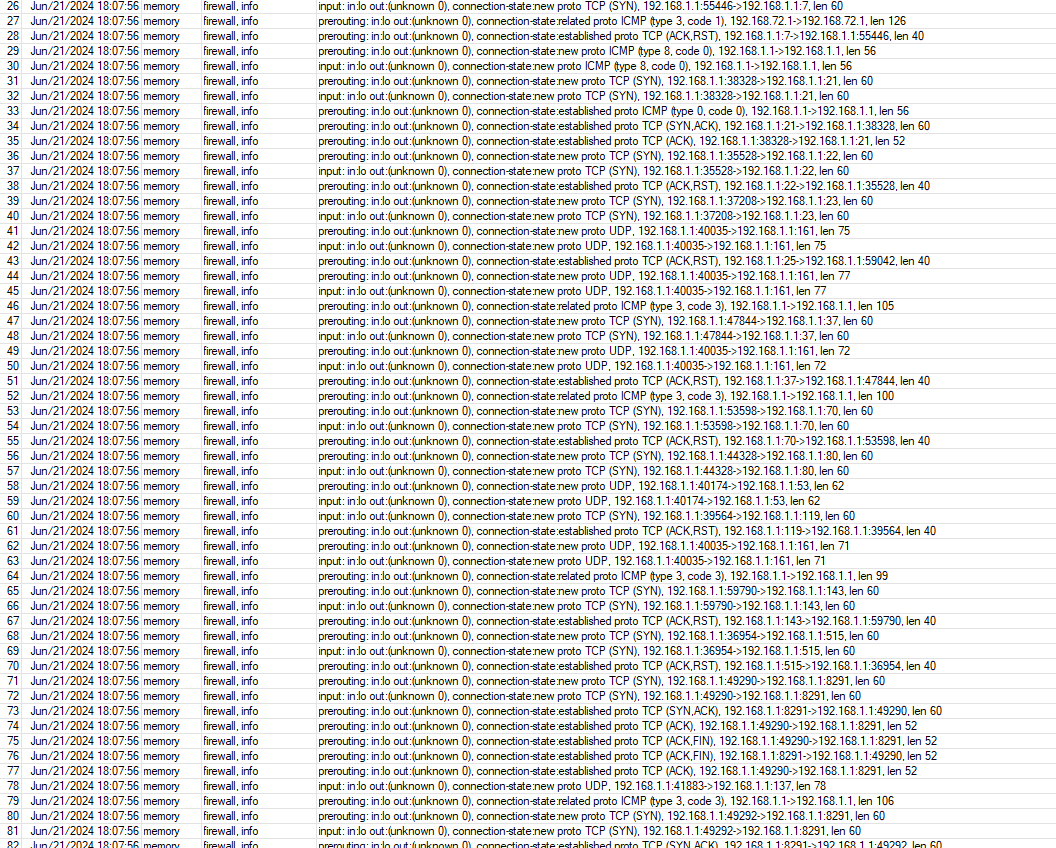
Also, I installed The Dude again to do a test. I set logging in firewall filter and raw to see what comes in through the lo interface. I attached an image of the log entries that appeared when I did a “reliable (scan each service)” scan of the 192.168.1.0/24 network in The Dude. When I do the same thing with the loopback rules set to allow from 127.0.0.1 instead of lo, The Dude doesn’t detect the router it runs on.
The WireGuard peers are routers on remote sites (mostly SXT LTE6 Kits on PV power plants) and most of them are behind CGNAT. The main location (with the Netwatch) has a public IP and the peers connect to that, they have persistent keepalive configured. The purpose of this setup is so that the main site has remote access to the peer routers for diagnostics and maintenance despite the CGNAT, and it works quite well, but we had issues where the LTE modems stopped working occasionally and somebody had to go and fix it on site. There is also an open case with Mikrotik support about this, we tried some things that were suggested there and it seems to work fine for now, currently we’re waiting to see if the issue will appear again in a few months or not (as it seemed to fork fine for a period of time after the router was brought to the office for us to check, nothing seemed wrong with it so it went back on site where it worked for a few months before issues appeared again). Their WireGuard interface’s IPs (such as 192.168.100.2, 192.168.100.3 etc.) are what’s being pinged. The purpose of the netwatch is to know when exactly the peer lost connection so we can look for something that might have happened at that time that might have caused the issue (a power surge/brownout, something else failing, a change in weather, temperature etc.).
All the cases you described fall into category of handling IP packets entirely in L3 of network stack and infotmation about interface name (either ingress or egress) is completely bogus. From your observation it does seem that ROS uses “lo” in this case.
BTW, I’m pretty sure that if there was a rule allowing connections originating from own IP address, then all of these cases would work even if using 127.0.0.1 instead of lo. But it’s a useless complication which doesn’t bring any additional security since all traffic “ingressing” via lo interface was already inside router before that.
So what would be the correct way to make it possible for The Dude to see its own router if
src-address=127.0.0.1
doesn’t work? Before the lo interface existed, I used
src-address-type=local
, is that the more correct way?
Also if the loopback traffic is handled entirely in L3 without even using interfaces, and the information about lo is just “tacked on”, then why was that interface even added at all? And would it really be that bad of an idea to use this tacked-on lo tag to identify loopback traffic in firewall rules?
Also, before lo existed, loopback traffic used to show up as “in:(unknown 1) out:(unknown 0)” in firewall logs. Maybe being able to identify CPU “interfaces” in firewall rules would be better? Or maybe CPU-to-CPU traffic should bypass the firewall completely, so we wouldn’t have to set up rules to allow loopback in the first place? But then someone might want to have it blocked for whatever reason.
The issue occurs because the router uses the WireGuard interface’s address instead of 127.0.0.1 for self-referential traffic. To fix this:
Force Self-Traffic to Use Loopback: Add a route or rule to ensure internal traffic always uses 127.0.0.1 as the source/destination.
Adjust Netwatch Settings: Suppress logging for unreachable peers or remove logging from related firewall rules. Anyone can explore more 127.0.0.1:62893 here.
Refine Firewall Rules: Update raw and filter rules to handle lo traffic explicitly and allow necessary traffic from 127.0.0.1 and WireGuard.
The Dude Scanning Issue: Ensure your loopback rules permit traffic from both 127.0.0.1 and the WireGuard interface to fix detection.
Check your router’s routing table and firmware for any updates to improve handling of these cases.