THis is the most interesting part about your post.
The packet is annotated with the connection mark in the conntrack phase. Until then, there is no associated connection mark. (On normal linux, wg interfaces have a property fwmark, which allows all packets emitted by wg to be marked on creation - this is not currently available on Mikrotik.)
Should I report this as a bug, or a recommendation? Is it outside the realm of wireguard protocol and just a function that linux applies to all such entities by design and perhaps MT was lazy??
I’ve tried routing rules and that does not work either. Its the wireguard goning default route or no route.
Had read the change log starting with 7.17 (I have 7.16.2) and ther is no mention of any fixing for wireguard. The problem is not with initial handshake where wireguard responds. But with subsequent packets were wireguard initiates the sending.
Do you mean the subsequent packets from the clients after they’ve connected to the WireGuard server, or are you referring to when the WireGuard server sends traffic back towards the clients, such as handshake responses or keepalive packets?
The subsequent packets from the client will go to the handshaked server IP. But from wireguard’s philosophy of being hidden, if from the server side a packed is send via wireguard, then here the src IP of wireguard which client expects will change.
WireGuard’s philosophy does not mean much unless there is a real issue to solve. If you are referring to a solid issue, like reply packets going out through the wrong WAN interface and the client rejecting them or something similar, could you please clarify what exact behavior you are seeing or referring to, as I asked in my previous post?
I just wanted to send a ping across. This is what I typed first. There’s no hidden agenda.
You are absolutely right that the source address is the issue, just not why. Wireguard always accepts correctly authenticated packets from any address. Either of two things actually go wrong:
If you emit a packet with a wrong source address (probably so wrong, it’s not even the same subnet or AS,) well-configured routers (by that I mean that they have some form of RPF enabled) simply drop these
If the packet manages to get to the other endpoint, it sets it’s “current endpoint address” to this source address
I’m not going to go into as much detail as I was initially inclined to do. Where the decision to apply src- or dst-nat to a connection is clear in the packet flow diagram. Where exactly the address translation happens is sneakily not shown in any of them. It might give a hint as to what is happening if we look at what we get if we enable logging for an src-natted packet:
(This has no relation to wireguard, just a general natted packet that came my way.)
firewall,info forward: in:vlan100-local-trusted out:wan, connection-state:established,snat src-mac 04:d9:f5:1e:33:71, proto UDP, 192.168.80.229:51413->81.183.229.86:1034, NAT (192.168.80.229:51413->89.133.122.28:51413)->81.183.229.86:1034, len 116
What we can surmise immediately from what we see is that all the information (the original source address, and the one it is replaced with) is readily available for netfilter to show. And it’s available for the entire journey it takes through the while netfilter framework, from the moment the connection is identified in the stage of processing usually labelled “connection tracking” until the time it leaves netfilter. The actual src-nat and dst-nat actions just modify these values and set flags. And when we match on the dst- or src-address (or ports) in some chain of the firewall, we are actually matching different addresses under the same name. Sneaky isn’t it.
Just to be very clear: the WireGuard protocol requires that the destination address of the initial handshake request MUST match the source address of the initial handshake response, otherwise the session will be dropped. If the handshake succeeds, then it is fine for the address to change, and WireGuard will update its internal endpoint accordingly.
sender := I_i (4 bytes) […] is generated randomly (rho^4) when this message is sent, and is used to tie subsequent replies to the session begun by this message.
And in section “5.4.3 Second Message: Responder to Initiator” it is clear that this is sent back to identify the session:
receiver := I_i (4 bytes)
So the handshake peer is indeed identified by its “sender id” (a random number) and not by its IP address.
I was not satisfied with this, so I took a look at the source code of the kernel implementation. The handshake request is validated in receive.c:
static void wg_receive_handshake_packet(struct wg_device *wg,
struct sk_buff *skb)
{
[...]
switch (SKB_TYPE_LE32(skb)) {
[...]
case cpu_to_le32(MESSAGE_HANDSHAKE_RESPONSE): {
struct message_handshake_response *message =
(struct message_handshake_response *)skb->data;
if (packet_needs_cookie) {
wg_packet_send_handshake_cookie(wg, skb,
message->sender_index);
return;
}
peer = wg_noise_handshake_consume_response(message, wg);
if (unlikely(!peer)) {
net_dbg_skb_ratelimited("%s: Invalid handshake response from %pISpfsc\n",
wg->dev->name, skb);
return;
}
wg_socket_set_peer_endpoint_from_skb(peer, skb);
net_dbg_ratelimited("%s: Receiving handshake response from peer %llu (%pISpfsc)\n",
wg->dev->name, peer->internal_id,
&peer->endpoint.addr);
if (wg_noise_handshake_begin_session(&peer->handshake,
&peer->keypairs)) {
wg_timers_session_derived(peer);
wg_timers_handshake_complete(peer);
/* Calling this function will either send any existing
* packets in the queue and not send a keepalive, which
* is the best case, Or, if there's nothing in the
* queue, it will send a keepalive, in order to give
* immediate confirmation of the session.
*/
wg_packet_send_keepalive(peer);
}
break;
}
packet_needs_cookie is only set if the handshake queue is too long (i.e. DoS)
peer is only determined by the message contents: peer = wg_noise_handshake_consume_response(message, wg)
And based on this, the endpoint address/port is updated and the session is started.
Nowhere is the source IP of the response validated, in fact the (current) endpoint address of the peer is updated based on it.
My use case have 2 mikrotiks. One acts as server (virtually as it has responder=yes), and another acts as client (virtually, no responder option set). From wireguard perspective both a peers (not servers not clients). So any of them can initiate communication to known IP address of another part. First via config if set, then via learned src IP.
Now to my example. Both mikrotiks have 2 ISPs. The wireguard are listen on 13231 port and on both mikrotiks this port is opened for input in firewall.
I witnessed two scenarious when mangling the rules on “server”.
The “client” start a first connection. The “client” send the packed randomly via one of the ISP to the IP address of “server” assigned to second ISP. The “server” receives the packet and by rules in firewall responds using second ISP and IP address. Back to “client”. Ok. As for know this seems to work ok. If a ping is generated from “server” to “client”, then the “client” will receive the packet from first ISP of the “server”, and because “client” is connected directly to internet and allows incoming packets to the 13231 port, it will receive it, mach the peer public key and will update the public ip of the “server” to the one received now. Then “client” sends back response to “server”'s ping but choose to emerge via first its provider. “server” receive that packet as it have the port opened and based of "client"s public key also updates "client"s current public IP. Subsequently both miktoriks use the first ISP of each one to communicate.
The “client” start first connection. The “client” send the packed randomly via one of the ISP to the IP address of “server” assigned to second ISP. The “server” receives the packet and no rules in firewall a configured, so “server” from start responds via first ISP to “client”. But because “client” have the port opened, it receives the response, recognize by the public key and updates the current endpoint IP. Then “client” sends a packed to “server” but choose to emerge via first its provider. And happens same as previous one.
Both mikrotiks will end up communicating via first ISP regardless of which initial ISPs or IPs were used. This is true if both of them have the input port opened.
Now think of “client” behind a firewall and is nated for accessing internet. (ie access via mobile data). “client” will not have any incoming port opened.
i had some free time to do a couple of tests today, and this point can be further simplified: we can just add a /32 address to the lo interface. No needs for the extra dummy bridge and the two separate IP addresses for src-nat and dst-nat.
Then 10.20.30.40 can be used instead of both your 172.16.10.1 and 172.16.10.2.
What i find interesting is that, until at least the middle of 2024, the srcnat rule was not necessary. I dug into my old chat logs with online acquaintances where we used to test and discuss this issue and this solution from @rplant used to be all what was needed: http://forum.mikrotik.com/t/wireguard-multi-wan-policy-routing/174145/1 My acquaintances and I did the small modification where instead of the dummy bridge, lo was used, other than that the single dstnat rule used to be enough. That did produce the effect that the reply to the handshake had the IP address of the lo interface as source. And the routing rule could steer it to the right table. I had assumed that was still the case when I wrote the reply in #5 of this thread.
But something must have changed in RouterOS in the 2nd half of 2024, because when I redid those old configs from last year today, the additional srcnat rule is now definitely required, as explained by @lurker888 multiple times in this thread.
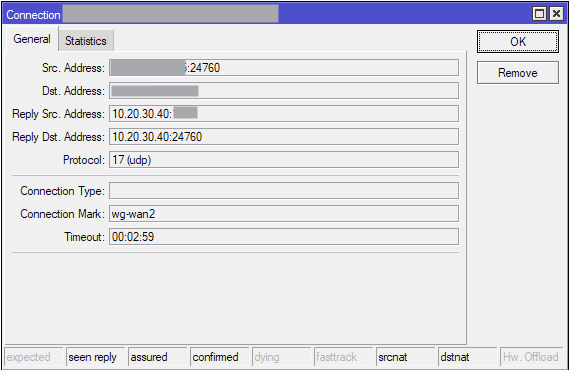
Sorry, I missed your post. Yes, it works with just a single IP address (which is a /32 address on interface lo under /ip address). I just tested again today under 7.19.4 by replacing the IP addresses in @lurker888's rules with only a single 10.20.30.40 address. Here is how the WG connection looks like in conntrack, with connection mark and srcnat + dstnat flags:
The screenshot has been censored, but "Src. Address" point to the 5G IP address of my phone, and "Dst. Address" is the WAN2 IP address of my router.
The srcnat and dstnat rules are there so that the WG packets can be matched with the existing conntrack entry, so that they can be associated with the connection mark. The response packets generated by WG on the router would have destination 10.20.30.40 port 24760, and in the main routing table there exists only a single route with destination 10.20.30.40/32, so this forces the source address of the packet to 10.20.30.40 too. For this tuple of dst/src address/port the conntrack entry with matching "Reply Src. Address" and "Reply Dst. Address" is found (the one in the screenshot).
So, there is apparently no requirement that "Reply Src. Address" and "Reply Dst. Address" have to be different. With @lurker888's rules above they'll have the addresses 172.16.10.1 and 172.16.10.2 respectively.
As for using lo instead of a new empty bridge: What we need is to give an IP address to the router and a limited route, so that there is only one possible source address to pick for a particular destination. As you know, adding an entry under /ip address automatically creates a dynamic route to the specified subnet too, with the chosen interface as gateway. You don't want to add the address/subnet to existing bridge & vlan interface already in use, because that modifies the routes associated with that interface. Before lo is exposed by RouterOS you would create an empty bridge that is not normally used to add this address and route. But with lo available you don't need to do that anymore.
And @lurker888's example adds 172.16.10.1/30, which gives the router the address 172.16.10.1 on the interface and the route destination 172.16.10.0/30 having that interface as gateway. That's why when the packet has destination 172.16.10.2 the source address 172.16.10.1 is chosen.
In my example I add the address 10.20.30.40/32 to the interface, which produces only a route with destination 10.20.30.40/32 but that's ok because the destination of the packet is also 10.20.30.40 and falls into the range of the route.