… now also allows type=FWD records (that forward to specific servers) to function with DoH? That’s on my wishlist for a long time (and requested in SUP-132300), and would be nice to finally have it.
Awesome update, but a couple of things, all related to webfig.
Active Class ID is a new field under /ip/dhcp-server/leases in webfig which is really cool but not listed in the changelog.
VLAN packet counters are wrong. It looks like VLAN ID - 1 is counting the total of all egress traffic that comes from any of the VLAN IDs while the appropriate VLAN ID is also showing that traffic. So if VLAN 5 is sending 500MB/s, then VLAN 5 TX will show that traffic (also has an issue outlined in point 3) but VLAN 1 will also have a TX rate equaling to 500MB/s. Only occurs with wireguard traffic (I didn’t test with other encryption like ipsec etc), and this traffic is cpu routed only it is never offload nor fasttracked.
3) VLAN TX/RX counters are incorrect when CPU-only traffic is flowing through the VLAN (ingress). The RX of the specific VLAN is correct but for whatever reason the TX shows double of whatever the RX is, when realistically if I am downloading to a device behind VLAN 500 at 2GB/s I expect to see the RX rate at 2GB/s and the TX rate < 10MB/s (maybe 5-10MB/s for tcp ack messages). — Not a true bug, just the effect of linux and wireguard calculations, maybe?.
EDIT: Point 3 is not a bug or I’m not entirely sure, I realized this only applies to wireguard connections. Point 2 also only applies to wireguard connections, for whatever reason.
Starting with ROS 7.16beta1 and now with RoS v 7.16beta2 my USB disk gets reset. This causes some of my scripts to fail.
Starting with Ros 7.15 Scheduler is still broken as it tries to launch my on STARTUP script … all the scripts have been tested and have zero errors … very annoying …
Yeah something is wrong with disk mounting or something.
On RB1100AHx4, it’s had ROSE installed since it was in beta and is my main test box, so it’s seen many beta/rc/etc’s. Disk/ROSE has never messed up BEFORE… But in 7.16beta1, all containers stopped worked and could not add new ones — figured out it was there was no disk mounts. My RAID1 setup was shown as “unknown” and nothing mounted in files, other the reference to a raid1-part1 disk that should have contained a bunch of files.
I tried upgrading to 7.16beta2, but disk still in “unknown” and not mounted state. Since recovery is not document and there was nothing important on the disk, I figured go to 7.15.1 and just re-create the RAID (since it had been same for as long as ROSE) in “stable” just to sure.
Nope… when I upgrade back to the 7.16beta2: Disks are back in “unknown” state and unmounted. Formatting/setting them up in 7.16beta2 also does not survive a reboot & goes to same “unknown” state (even without a more complex partition scheme I had before):
LMK, I can file bug report if needed, but given @mozerd’s comments, I’m guess something more generically is wrong in /disk in 7.16beta1/2.
*) poe-out - upgraded firmware for SAMD20 PSE (AF/AT) controlled boards (the update will cause brief power interruption to PoE-out interfaces);
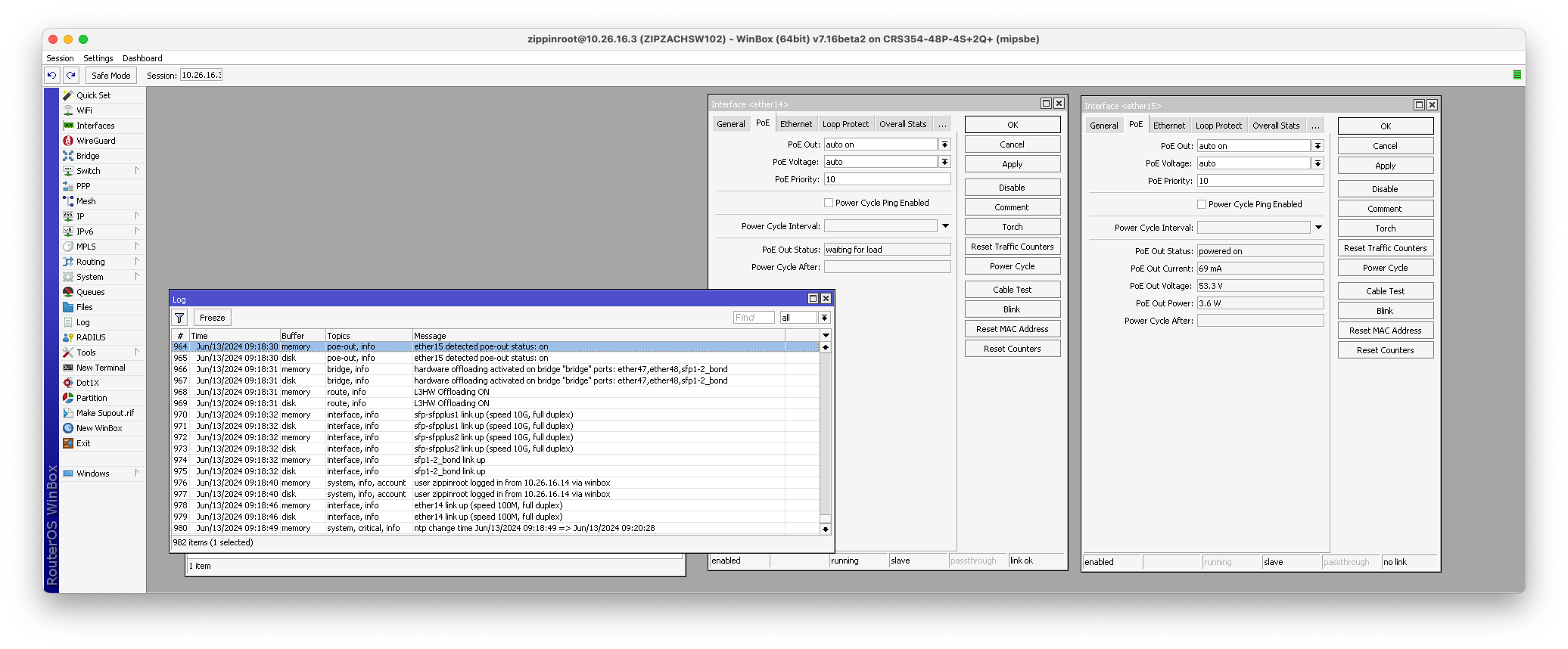
PoE statistics are off by 1 port on beta2. I have only 1 device plugged into ether14, but PoE statistics show on ether15. This is on my CRS354-48p-4S-+2Q+. You can see the log show ether15 powered on PoE and then ether14 showing the link.
That was the solution up until now. It was not enough for some users. Previously, changes were divided “change in this release” and “other since previous stable”.
Issue 1) Upgrading from 7.16beta1 to 7.16beta2 from WebFig caused my CRS518 to crash completely (necessitated a hard power cycle).
Issue 2) After upgrading from 7.16beta1 to 7.16beta2 on my CCR2216, IPv6 prefix delegation configuration disappeared completely; global IPv6 addresses were also not delegating to my VLAN interfaces. Downgrading to 7.15.1 stable restored both the configuration and IPv6 global addresses.
Edit:
Issue 3) On both 7.16beta1 and 7.16beta2 on my CCR2216, it appears that running dual stack (IPv4 and IPv6) and having firewall rules that permit both versions of traffic disables hardware offloading for IPv4. Blocking all IPv6 traffic with a simple firewall rule (but leaving the IPv6 addresses in place) restores hardware offloading for IPv4. Definitely an odd behaviour.
Perhaps. It may be specific to ROSE + RAID in my case.
I narrowed down the issue after several reboot, re-formats, etc. Turn out the raid’ed hardware disks (sata1 and sata2) lose their “raid-master=raid1” settings. So adding the “lost setting” back manually restores the raid (without data loss). But this seems to be needed after EVERY REBOOT of v7.16beta2 - so not just after upgrade:
/disk set sata1 raid-master=raid1
/disk set sata2 raid-master=raid1
It might be a timing issue. I added those the settings now to a “startup” scheduler…but took adding a “:delay 2s” before them for it to work.