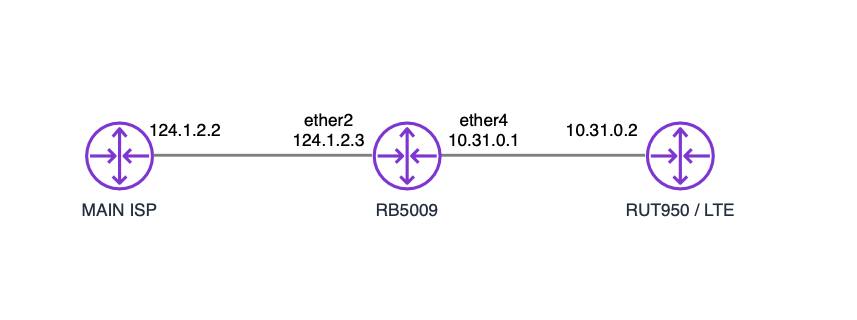
I am setting up dual WAN failover using netwatch and scripts to manipulate two 0.0.0.0/0 route distances and need to check if my main ISP is back up before bringing up the main ISP default route.
During testing (with Main ISP still up) I can’t ping via ether4 to 8.8.8.8.
I used /ping interface= in my testing environment and it worked. But not on the real gateway. It worked for one interface and did not for the other. Both interfaces were ethernet with fixed ip.
I’m using right now:
ip vrf add name=Test1 interfaces=none
/ip route add gateway=<nexthopp on ether1> routing-table=Test1
With this setup /ping 8.8.8.8 vrf=Test1 works. In case it does not work for an interface I just increase in routing rule the distance. A mistake here is not a game changer in my case.
I’ couldn’t find more info about how a vrf with interfaces=none works and I also cannot say anything about weather this is the right way.
(RoS v 7.16.2)
Likely the route via 124.1.2.2 will be AS (Active Static) whilst the one via 10.31.0.2 will be only S (Static) (due to the bigger distance).
A route that is not active is like it doesn’t exist.
You will have also a DAc (Dynamic Active connect) route for 10.31.0.0 on ether4 and one (still DAc) on ether2 for 124.1.2.0, these are automatically created from the IP addresses you assigned to the interfaces.
So what happens should be:
you ask for 8.8.8.8 on ether4
there is a route on ether 4 is for 10.31.0.0, and clearly 8.8.8.8 is not part of that range
there is no route for 8.8.8.8 (as contained in 0.0.0.0) using ether4
When you use the other interface:
you ask for 8.8.8.8 on ether2
there is a route on ether2, it is for 124.1.2.0, and clearly 8.8.8.8 is not part of that range
there is an Active route for 0.0.0.0 (that contains 8.8.8.8, via ether2)
this route is taken and via the gateway 124.1.2.2 the 8.8.8.8 is reached
/ip/route/print
Flags: D - DYNAMIC; A - ACTIVE; c - CONNECT, s - STATIC
Columns: DST-ADDRESS, GATEWAY, DISTANCE
# DST-ADDRESS GATEWAY DISTANCE
;;; primary_route
0 As 0.0.0.0/0 124.1.2.2 1
;;; secondary_route
1 s 0.0.0.0/0 10.31.0.2 2
DAc 10.31.0.0/29 ether4 0
My failover script changes the route distance on ether2 to ‘3’ enabling the default route via ether4. I was hoping I could use ping 8.8.8.8 interface=ether2 to periodically check if the primary WAN was back up but my testing (I am currently testing around the other way, that is, try gin to ping out via ether4) shows that this will not work.
But nothing prevents you from adding a “narrow” /32 route via ether4 for the chosen address (since 8.8.8.8 is more widely used, better IMHO 8.8.4.4 for this use or another DNS server).
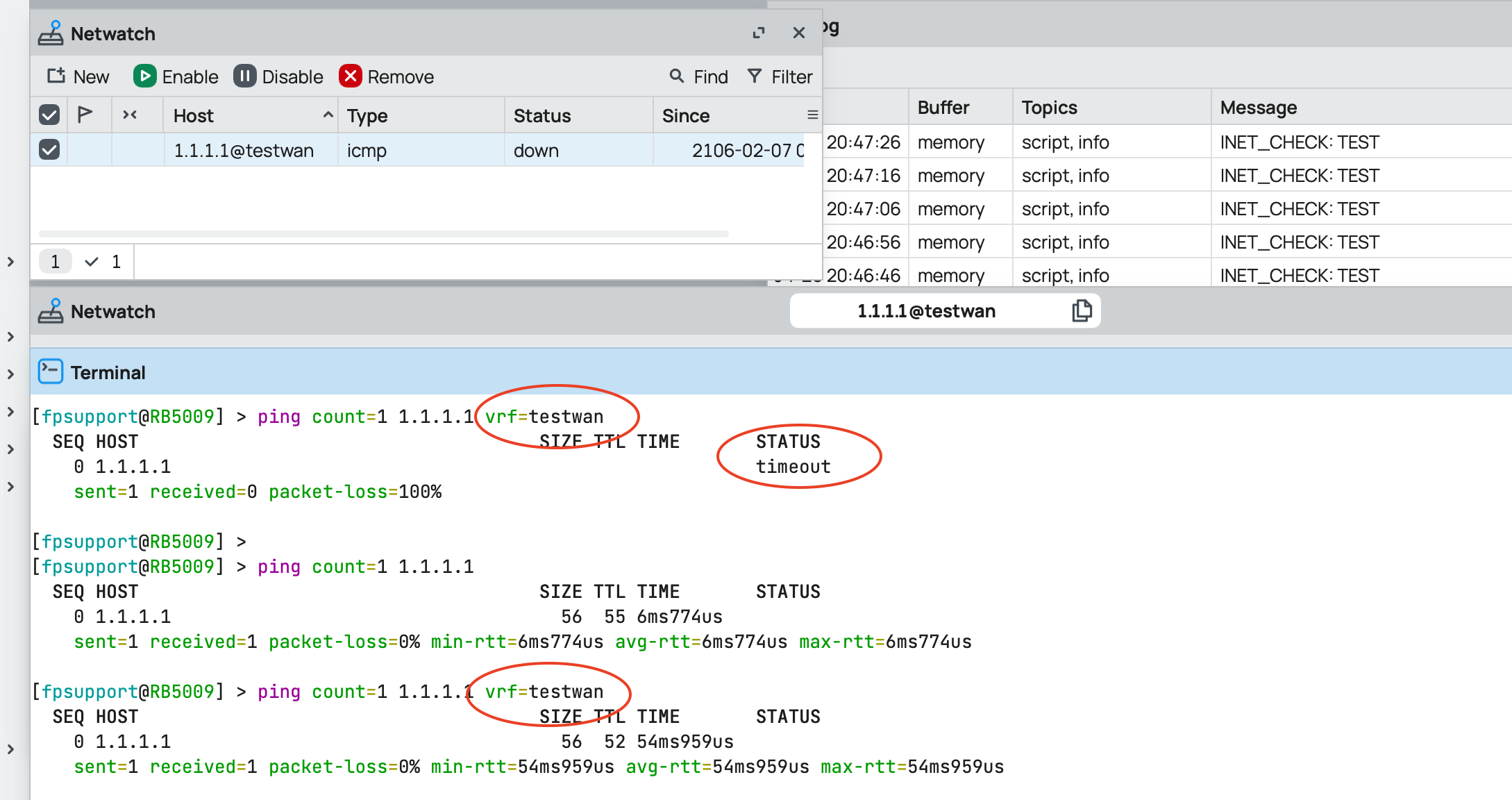
This seems buggy… I went into winbox and tried to use the GUI ping tool to 8.8.8.8 via the test wan vrf and it failed. I clicked ARP ping, it failed, delselected and it then pinged via the test wan vrf.
Netwatch leaks out any wan to find a connection and thus you need to blackhole any netwatch routing with a second following route same table distance add one.
I was trying to do this without using the 8.8.8.8/32 narrow route hence trying to ping via the down (primary) interface. At the moment the second VRF / route table method is working.
Edit: I spoke too soon. This morning the VRF method no longer allows a ping to 8.8.8.8 but again traceroute works:
Decided to use the suggested /32 route but using 4.2.2.2 so no DNS is interrupted during failover. Using ICMP probe type in netwatch. This seems to be working.
The only difference I see in the routing through 10.31.0.2 is that in vrf there is no suppress-hw-offload=no. I would like to know if it makes any difference?
Aside, but what’s the current best practise around WAN failover to LTE? When I last did this, we were still on RouterOS v6. Is the method/support different in RouterOS 7? From memory, it was mainly PING tests plus scripting.
I don’t think there is unanimous consent on the matter, basically it is recursive vs. netwatch, each one has some slight different features, but if properly implemented they both work just fine in most setups.
Then some people believes that the one (or the other) can be bettered or fine tuned by complicating the one or the other with sophisticated scripts, and again as long as they work, they are just fine.
Only as a side-side note, there is also a (not yet tested/reported about AFAIK) newish approach hinted about in Mikrotik’s help page for Netwatch ICMP testing, making use not of the reply of the canary address, but leveraging on a low TTL exhausting on an intermediate hop : https://help.mikrotik.com/docs/spaces/ROS/pages/8323208/Netwatch
accept-icmp-time-exceeded=yes can be used together with a manually set low ttl value to monitor Internet connectivity, without relying on a specific endpoint.
For example, you can monitor a public IP address, but that address can filter your ICMP request, or just become unreachable itself, if the Netwatch probe is using this address to monitor Internet connectivity this would cause a false alarm.
To make sure you can reach the Internet, it’s generally enough to make sure you can reach a device a few routing hops away. Low time to live value will expire in transit to the specified host you want to monitor - each router passing the ICMP packet will subtract “1” from TTL value, upon TTL reaching 0, ICMP “time exceeded” packet will be generated, and sent back to the Netwatch probe. If all other fail thresholds are not broken, this response will be considered a success.
I did read this note the other day and didn’t get time to test it further. I have looked at it tonight and It is actually a clever method of determining if a link is up or down.
I would like to use netwatch but there is simply not enough documentation around how it considers a connection back up. In my testing with both simple and ICMP probes it seems that after 1 successful ICMP response the link was deemed back up, I need better odds on a link up transition.
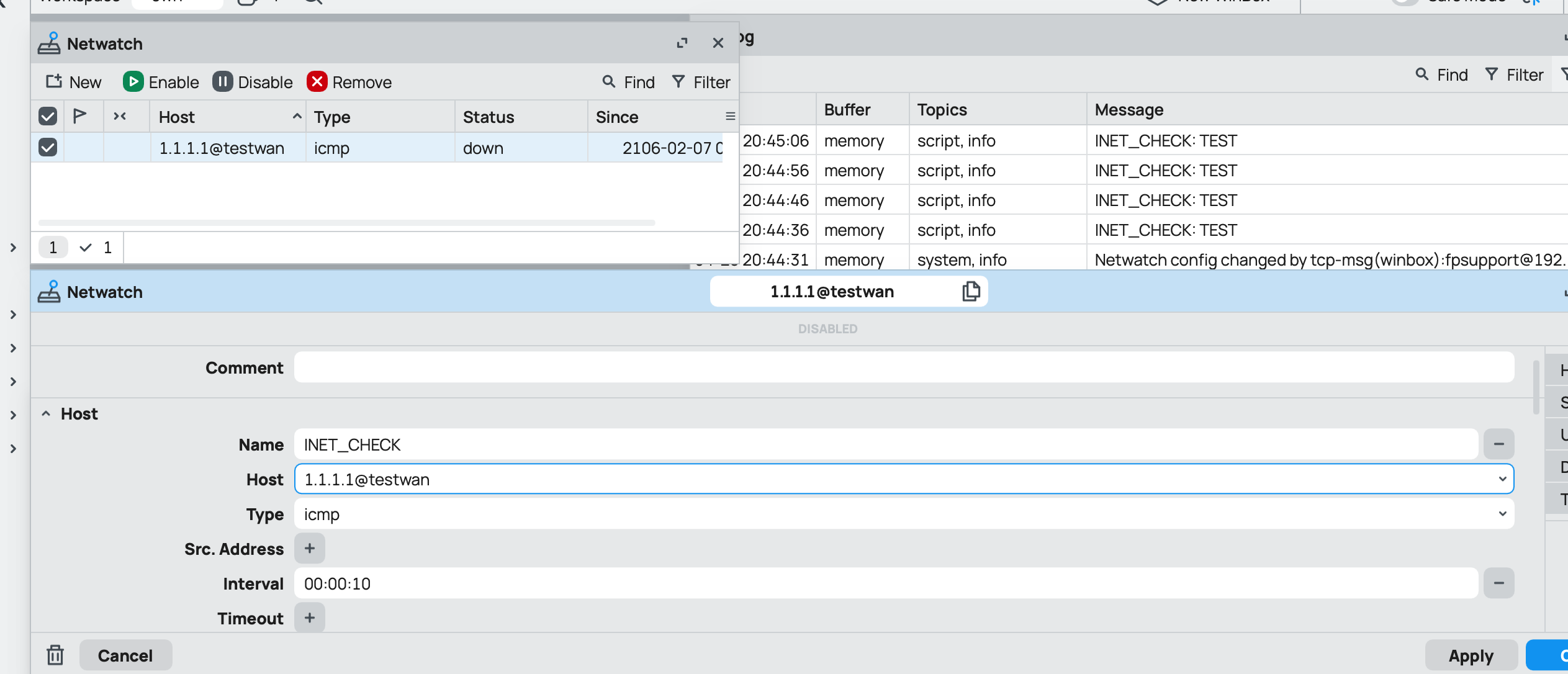
I noted that the Netwatch doco mentions the ICMP probe accepts a vrf option so I thought, great, I can set up an interface=none vrf and then a static route to 1.1.1.1 via this vrf so that in a failover (which could last for hours) network devices still had access to 1.1.1.1 DNS. Unfortunately netwatch seems to suffer the same issue I documented here: http://forum.mikrotik.com/t/dual-wan-failover-script-feedback-pls/183423/1 in that when pinging via a vrf the device requires one successful ping via the main vrf before it will send ICMP packets via the specified vrf: