Hi guys,
I’m running into a problem of which I don’t have the faintest idea how to get this working the way I want it to work..
The case itself is pretty easy..
We’ve sensorprobes measuring relative humidity in % and/or temperature in degrees C via SNMP.
In the real-life example below I use the settings I currently use for monitoring RH in %
I created a function that graphs the returned value, but.. there seems to be something going otherwise then I would expect it…
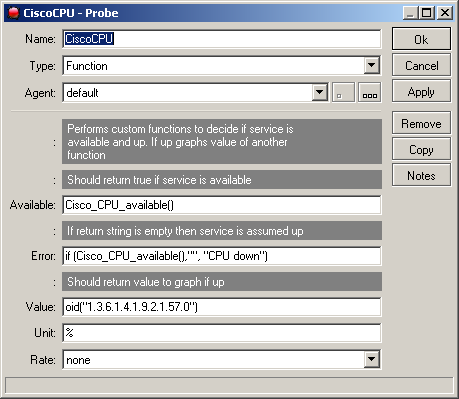
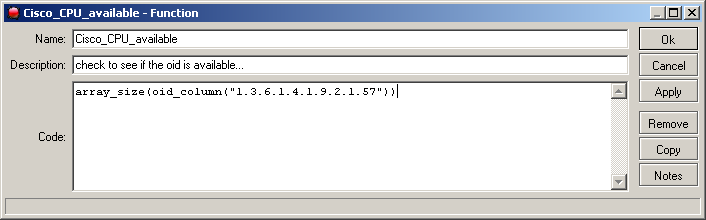
First of all The Dude checks if the OID is available
When the returned value is below 30 % or above 70 % the value enters error state.
Then I expect the function to graph the returned value and make sure it displays the fact I use %.
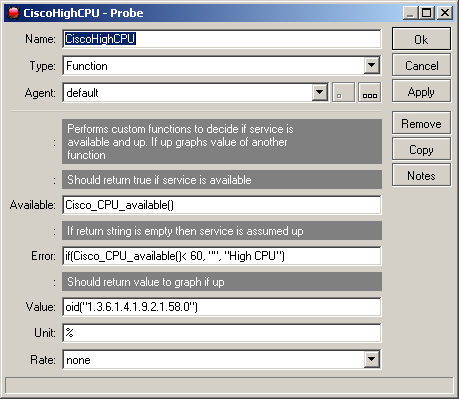
Since the whole problem is similar with the function for the temperature I will skip that one..
Below is the function, below the function I continue explaining what is not working with me..
NAME: RH #1
TYPE: FUNCTION
AGENT: DEFAULT
AVAILABLE: if(oid(“1.3.6.1.4.1.3854.1.2.2.1.17.1.3.0”)>0,1,-1)
ERROR: if(or(oid(“1.3.6.1.4.1.3854.1.2.2.1.17.1.3.0”)<30,oid(“1.3.6.1.4.1.3854.1.2.2.1.17.1.3.0”)>70),concatenate(“Relative Humidity out of range. Value = “,oid(“1.3.6.1.4.1.3854.1.2.2.1.17.1.3.0”)),””)
VALUE: oid(“1.3.6.1.4.1.3854.1.2.2.1.17.1.3.0”)
UNIT: %
RATE: none
Whenever the returned value is within the threshold everything does what it is supposed to do..
The value is in OK state, nothing wrong there. The function graphs the value as expected and colourstate is green.
But.. when the returned value is below or above the configured threshold the function does enter error state, but the values don’t get graphed any more, colourstate changes to something not green.. Since I’m a disaster in coding functions I’m begging for help here.. ![]()
My request/question is..
Is it possible to make sure the value gets graphed even when it is in error state which ofcourse should be propogated within the Dude for further processing like alerts/changes in colourstate etc?
I think it is better to see a value drop or spike outside the threshold than ignoring it at all when in error-state.
Maybe it is possible to create the threshold within the Dude in another way, eg entering OID and min/max values?
Maybe the coding for function could/should have functionality to create graphs even when values are in error-state by ticking a box?
Personally, I wouldn’t be surprised if this behavior is partly responsible for the gaps in the graphs within the Dude.
It could explain the empty places within graphs when the graph depends on (builtin) functions which return a value in error-state. (imagine ping to time-out in 3 sec, this function/probe to return frequently > 3sec would give gaps in the graph).
I hope to hear from you guys!
Best regards,
Minollie