We’d use to have a simple routed network. (And bridged or switches in some places.) Central dhcp-servers assigned clients of IP’s and each AP had its own network and was routed towards from the gateway.
To upgrade our service level and improve the quality of the network (redundancy!) we started to work with OSPF on parts of the network. Use mpls/vpls from gateway towards remote traffic concentrators (router serving several AP’s) and for client authentication we have several PPPoE servers (one at each VPLS interface).
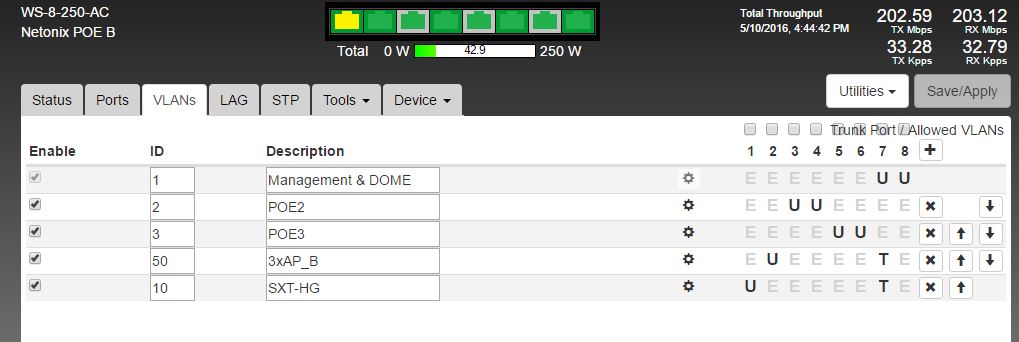
At some parts of the network we also have vlan’s to make local fixed line clients connect to same VPLS as building’s AP clients.
Apart from that, in several locations of our AP’s we have 2,4Ghz hotspot APs’ that all connected to a dedicated vlan network running over the same physical network as the rest.
Actually since we started to implement the pppoe to the clients which should improve things (we sorted some switches and separated traffic in routers) we are getting more and more complaints from clients saying their internet is sooo slow or they only can get half the speeds of what they are believed to have signed for.
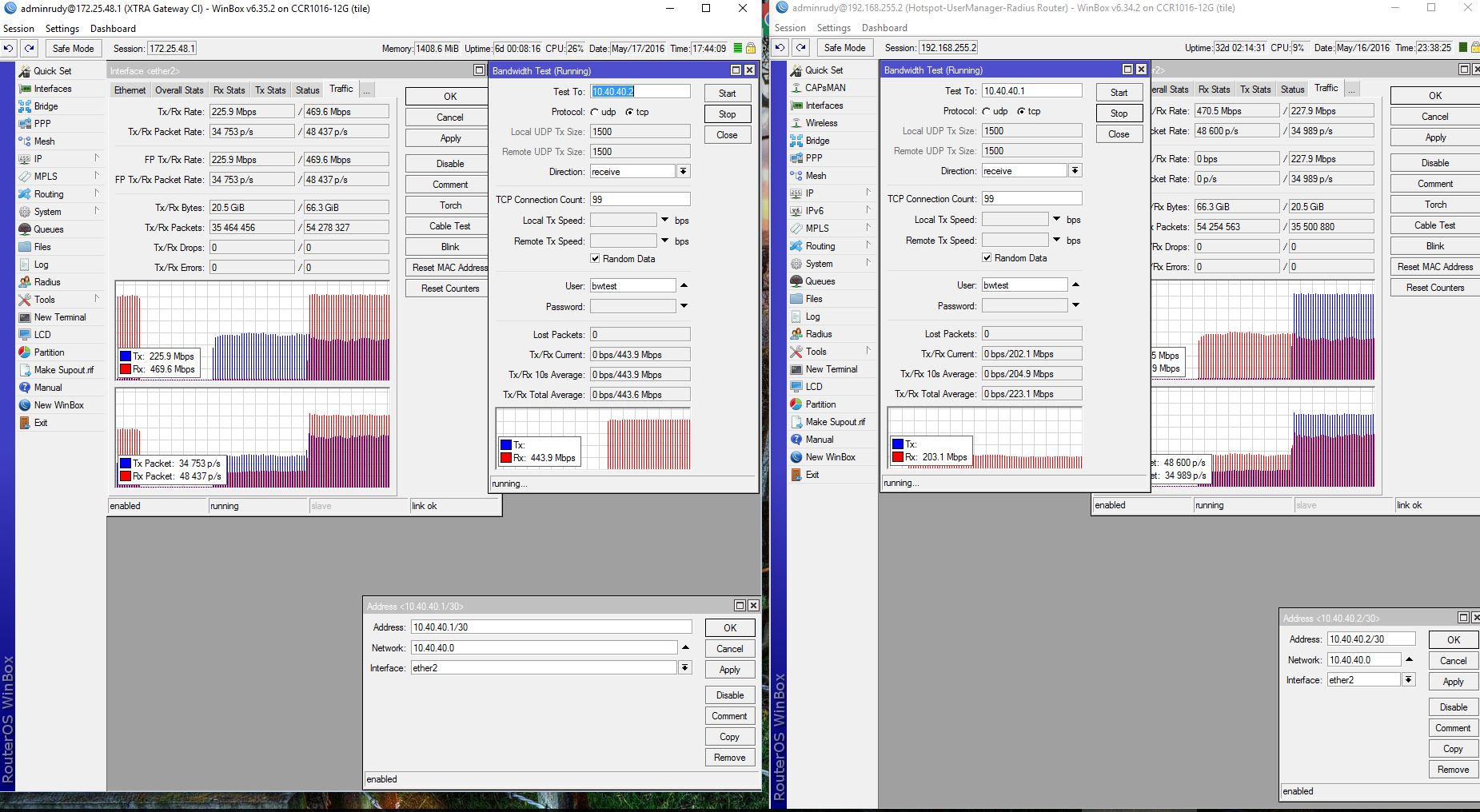
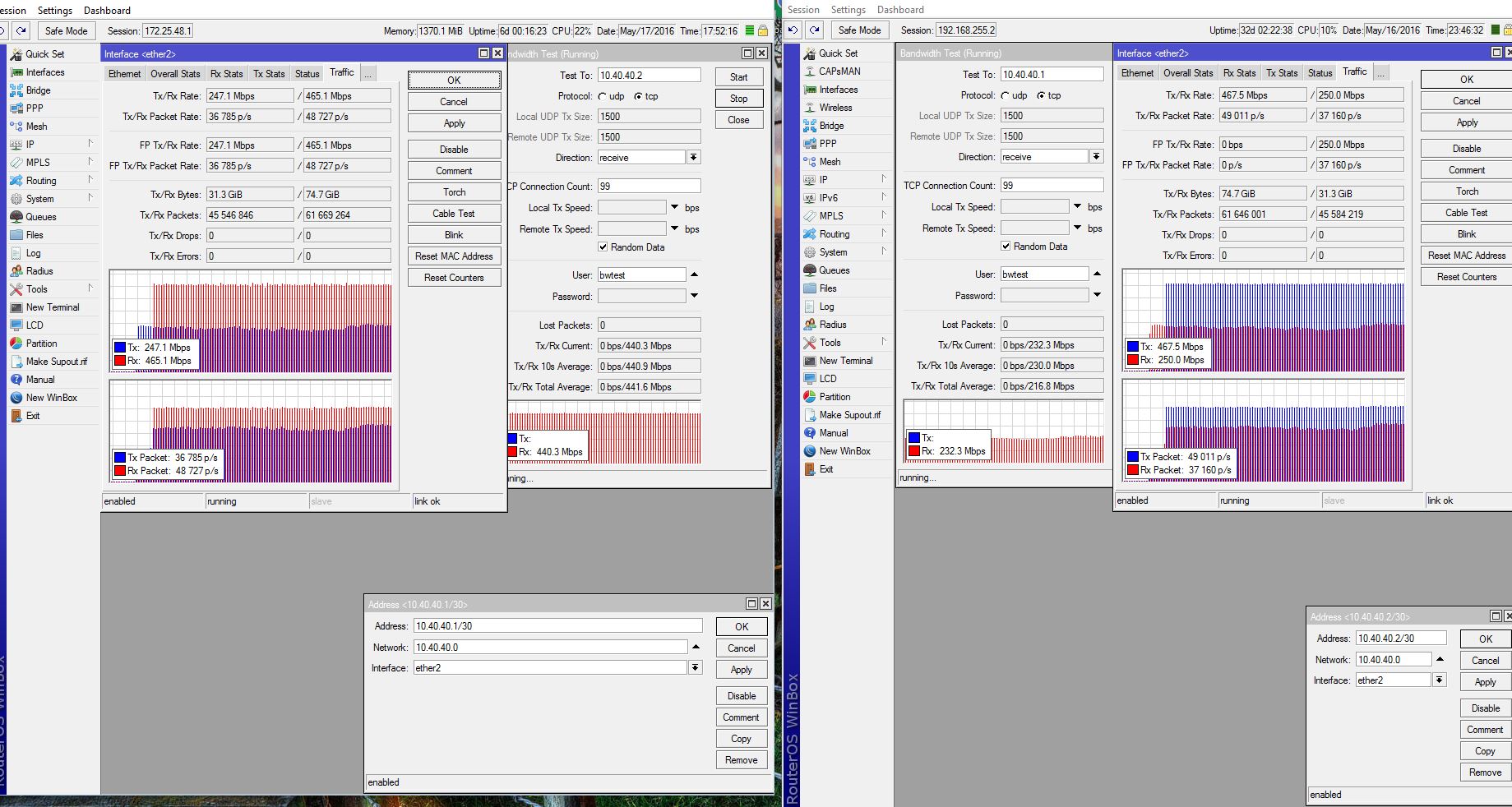
Each and any time we can run MT bandwidth tests from client’s CPE (SXT’s) and always get the full assigned (simple queue by pppoe server) capacity. But tests done from clients premises reveals indeed only half of that is getting into the clients network… how come?
Recently we found an issue might be the mtu setting of the Mikrotik routers.
Now I can find several technical explanations with a lot of tech talk which is all hard to understand by me, but the bottom line is, how do I set, and which, Mikrotik routers? Is there not one setting that arranges all?
And where? Only in some major routers? Or in any router/switch settings needs to be set?
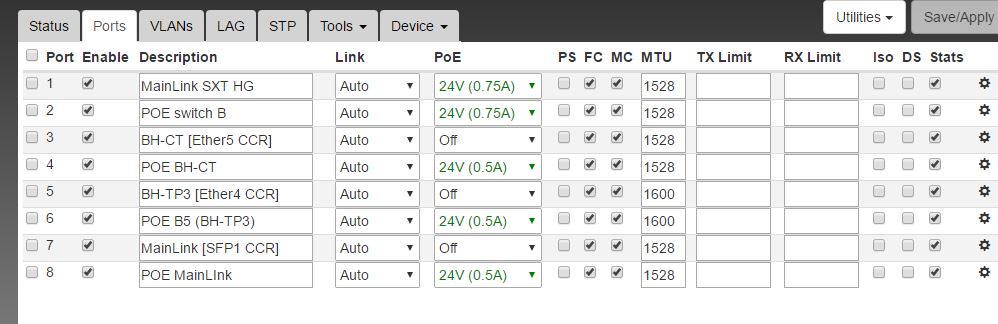
[Apart from 4 Netonix Switches the whole network consists of modern MT devices (some rb411’s still around as CPE).
Off course, client’s wifi routers are several brands, usually TP-Link and our gateway CCR connects to the Cisco of our bandwidth provider.]