Some thoughts to lower the CPU load on your CHR. This is what I do on my CHR hosted on VMware ESXi.
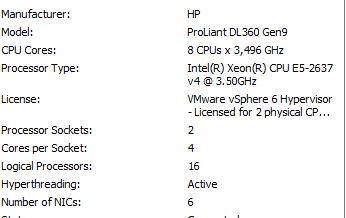
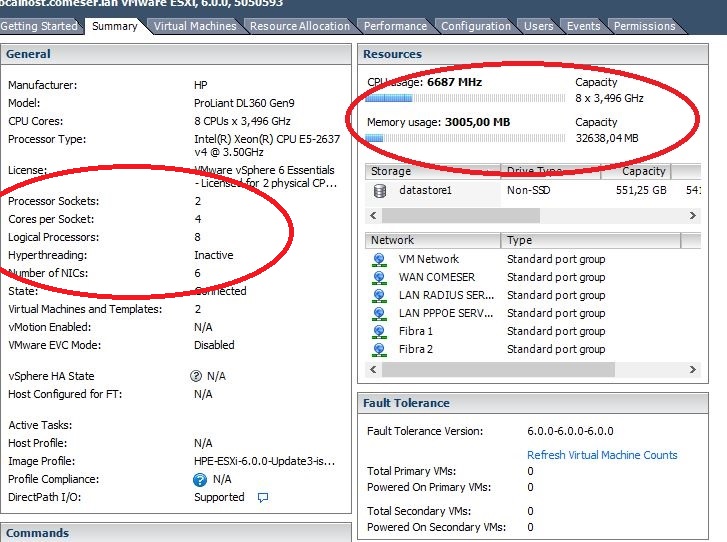
1)- consider swapping out both of your Intel Xeon E5-2637 processors to an Xeon E5-2690.
I have found that CPU built-in cache is more important than CPU clock speed - especially when running tiny hosts which mostly run in CPU cache.
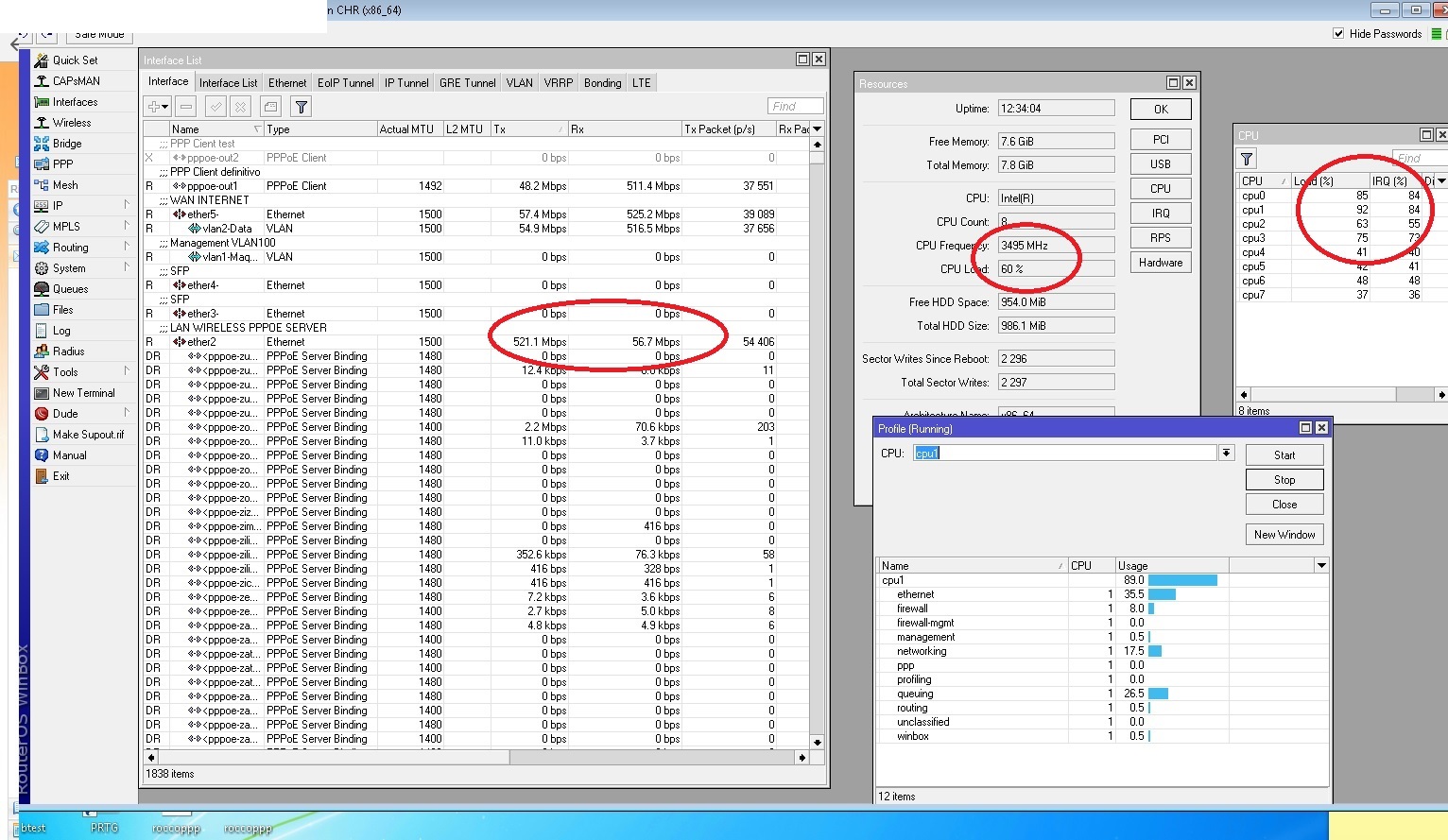
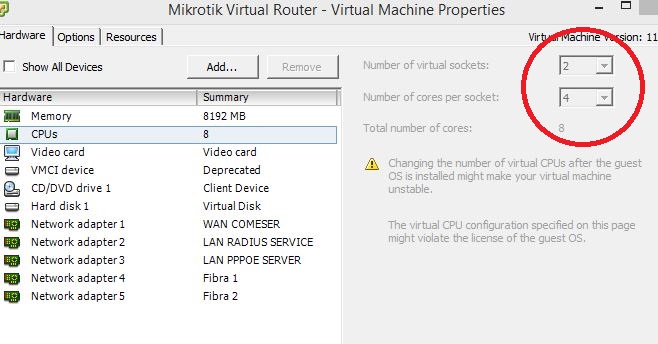
2)- It looks like you have hyper-threading enabled. Disable it. Hyper-threading cuts your build-in Xeon CPU cache in half and also slightly slows down the system because you have your Xeon processor emulating twice as many processors. This costs CPU throughput. Never use hyper-threading. Hyper-threading is only good for systems that can not be hardware upgraded where you need more CPUs (at the cost of slowing down the entire system to make it appear that it has more CPUs).
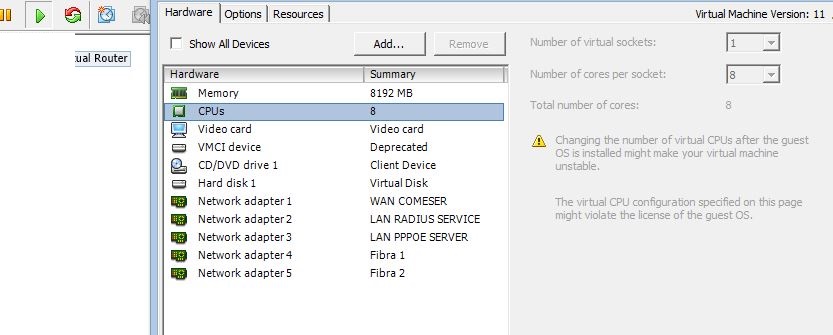
3)- There may be some issues with your 5 (five) network cards.
Each network card should use a unique CPU interrupt. If I remember correctly, you can go up to 4 networks card with unique interrupts. Five (5) network cards and higher will start using shared interrupts. Shared interrupts slow down the system because the operating system now has the added job of determining which device triggered an interrupt.
4)- Configure your VMware ESXi so that the next time you boot/power-on your CHR - that you end up going into the BIOS.
In the BIOS, disable/remote the following
serial ports
floppy drive
CD drive
Each of these in-necessary in-used devices has an interrupt associated to the device. There is no point in having the CHR check these devices to see if they generated an interrupt.
5)- network cards for CHR via VMware ESXi
— If drop down to a max total of only 4 network cards !!!
— If can use 802.1q vlans on your CHR - it works pretty well
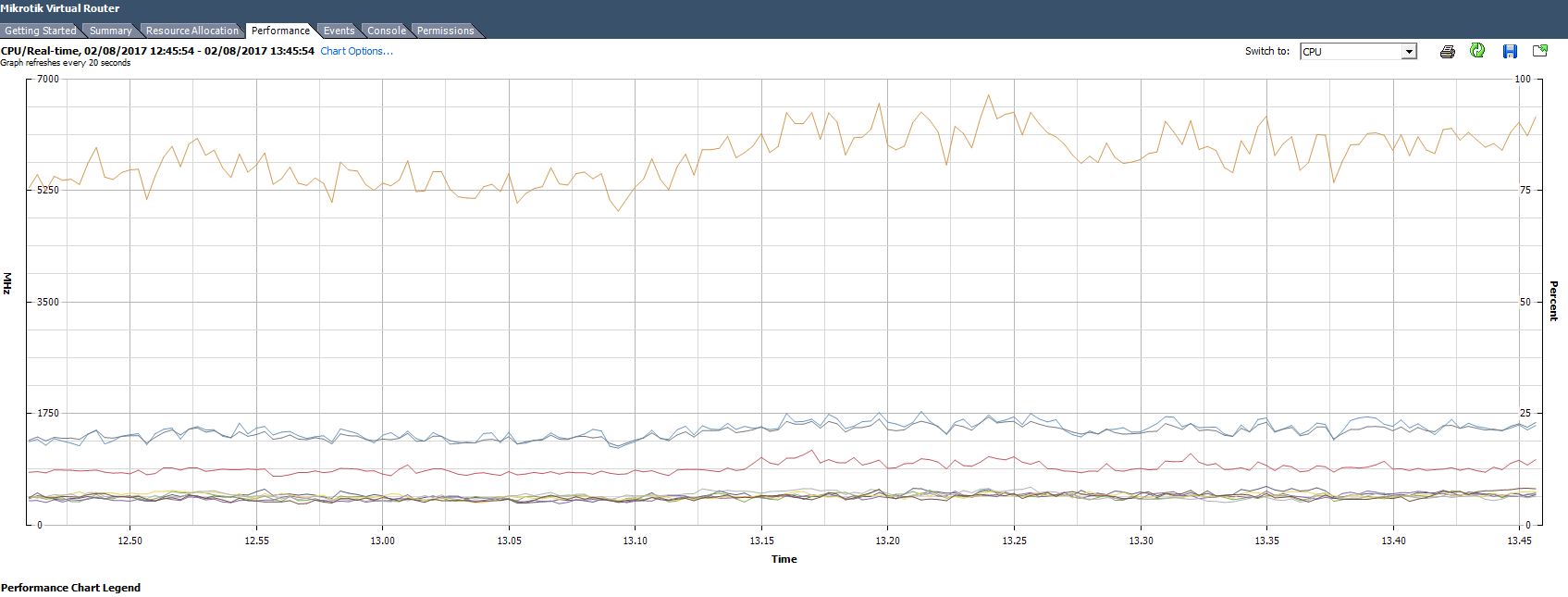
6)- After all of the above … Perform a btest ( UDP send ) to 127.0.0.1
With your older/slower Xeon processor, I would guess you should hit 2-gig to 11-gig.
My CHR best to 127.0.0.1 reports 17 to 19 Gig.
FYI - 127.0.0.1 is an internal IP address in your CHR. Kinda like a built-in internal virtual network card.
If you tweak and settings to improve your CHR, get a base-line btest to 127.0.0.1 prior to making any changes. The faster the btest to 127.0.0.1, the faster your CHR is running.
7)- If you have other virtual hosted machines on your VMware ESXi server … then as a test , stop/shutdown the other servers then run a btest to 127.0.0.1 and see if there is any difference.
8 ) - You should always get much better/faster network throughput if you Intel 10-gig network cards
9)- On your VMware ESXi server, go into the BIOS on your physical machine. Delete/remove any devices you do not need (you want to keep the physical interrupts down so that your VMware ESXi physical server does not spend a lot of time processing interrupts - which in turn slows down everything it hosts). Disable all power management and set BIOS for maximum performance.
10)- VMware ESXi, edit your CHR settings (console - edit - Options - General … then disable logging)
11)- If you know how to, convert any hosted machines on your VMware ESXi box “Hard disk #” from “thick” to “thin”. Do this for all guest hosted machines on your physical VMware ESXi server.
EDIT:
12)- Every hosted guest machine and including the CHR should be using VMXNET-3 network cards. This is a paravirtual optimized network card to enhance network throughput and lower the CPU cost to operate the network interface.
Post something if anything here helps
North Idaho Tom Jones