I’ve recently posted about the excellent rose storage server and how great it was working for me.. but I’ve broken my environment since then because I formatted the disks from 512 to 4k LBA (I believe is the root cause).
My personal problem is the server is in an entirely different city… so I need to fly back to and collect the disks, format them back to 512 and reinstall them…. so hopefully we can find a software solution I can fix remotely. ![]()
A support ticket has been raised (SUP-206829), but I’m hoping the community might be able to validate and find a work around with me.
Hello team,
I’ve got a NVME over TCP setup on my proxmox cluster. connected to a RAID6 cluster of disks on a ROSE.. this is going to be a long one.
I have a ROSE running testing 7.21rc2
it is filled with 2 groups of disks
10 x SAMSUNG MZQLB960HBJR-00W07
9 x SAMSUNG MZQLB960HAJR-00007These disks have all been formated with LBA1 (4kn) over the 512b (I think this might be the first problem and Rose doesn’t support 4k? maybe?)
they are setup in a RAID6 with 9 disks
they are both setup with NVME over TCP
add nvme-tcp-export=yes nvme-tcp-server-nqn=nqn.2000-02.com.mikrotik:raidPM983 raid-device-count=9 raid-type=6 slot=raidPM983 type=raid add nvme-tcp-export=yes nvme-tcp-server-nqn=nqn.2000-02.com.mikrotik:raidPM983a raid-device-count=9 raid-type=6 slot=raidPM983a type=raid set nvme1 raid-master=raidPM983a raid-role=0 set nvme2 raid-master=raidPM983a raid-role=1 set nvme3 raid-master=raidPM983a raid-role=2 set nvme4 raid-master=raidPM983a raid-role=3 set nvme5 raid-master=raidPM983a raid-role=4 set nvme6 raid-master=raidPM983a raid-role=5 set nvme7 raid-master=raidPM983a raid-role=6 set nvme8 raid-master=raidPM983a raid-role=7 set nvme9 raid-master=raidPM983a raid-role=8 set nvme10 raid-master=raidPM983a raid-role=spare set nvme11 raid-master=raidPM983 raid-role=0 set nvme12 raid-master=raidPM983 raid-role=1 set nvme13 raid-master=raidPM983 raid-role=2 set nvme14 raid-master=raidPM983 raid-role=3 set nvme15 raid-master=raidPM983 raid-role=4 set nvme16 raid-master=raidPM983 raid-role=5 set nvme17 raid-master=raidPM983 raid-role=6 set nvme18 raid-master=raidPM983 raid-role=7 set nvme19 raid-master=raidPM983 raid-role=8they are both connected to 2 proxmox nodes in a cluster
MAJOR ISSUE:
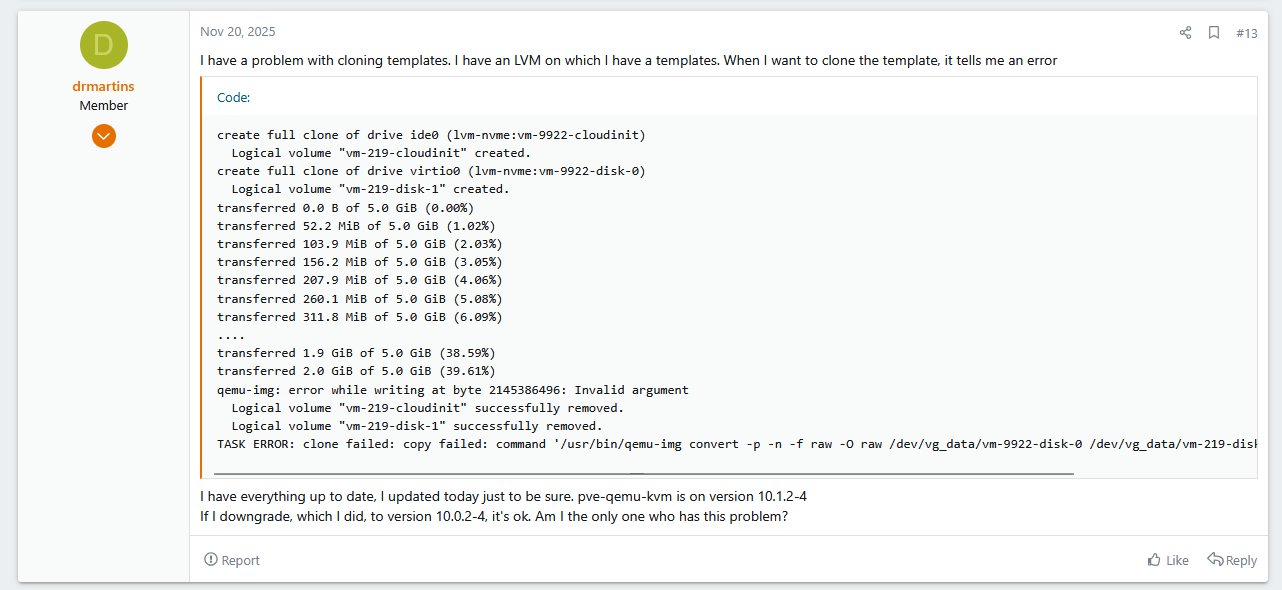
When I try to migrate to the VM from local storage to the nvme over tcp disks which is formated with LVM:this happens on both nvme4n1 (/dev/vg-rose-raidPM983) and nvme5n1 (/dev/vg-rose-raidPM983a)
and failed at the exact same byte qemu-img: error while writing at byte 2145386496: Invalid argument on both NVME.
Wiping PMBR signature on /dev/vg-rose-raidPM983/vm-123-disk-2. Logical volume "vm-123-disk-2" created. transferred 0.0 B of 50.0 GiB (0.00%) transferred 512.0 MiB of 50.0 GiB (1.00%) transferred 1.0 GiB of 50.0 GiB (2.01%) transferred 1.5 GiB of 50.0 GiB (3.01%) transferred 2.0 GiB of 50.0 GiB (4.02%) qemu-img: error while writing at byte 2145386496: Invalid argument Logical volume "vm-123-disk-2" successfully removed. storage migration failed: copy failed: command '/usr/bin/qemu-img convert -p -n -T none -f raw -O raw /dev/zvol/SSD/vm-123-disk-1 /dev/vg-rose-raidPM983/vm-123-disk-2' failed: exit code 1
- The raw storage device information gives me
Device: nvme4n1
max_hw_sectors_kb : 2147483644
max_sectors_kb : 7168
logical_block_size : 4096
physical_block_size : 4096
minimum_io_size : 4096
optimal_io_size : 7340032
discard_max_bytes : 2199023255040
discard_granularity : 4096
write_cache : write back
nr_requests : N/A
rotational : 0
alignment_offset : N/ADevice: nvme5n1
max_hw_sectors_kb : 2147483644
max_sectors_kb : 7168
logical_block_size : 4096
physical_block_size : 4096
minimum_io_size : 4096
optimal_io_size : 7340032
discard_max_bytes : 2199023255040
discard_granularity : 4096
write_cache : write back
nr_requests : N/A
rotational : 0
alignment_offset : N/AAccording to the basic docs..
max_sectors_kb defaults to 512
max_hw_sectors_kb defaults to 512… looks like it’s currently an signed 32bit value?!optimal_io_size defaults to 0…
I hope this helps you diagnose the issue… I will leave the disks in the Rose and travel back home… happy to test debug firmware because nothing will use it.
More information
https://www.kernel.org/pub/linux/utils/util-linux/v2.23/libblkid-docs/libblkid-Topology-information.html
OPTIMAL_IO_SIZE: usually the stripe width for RAID or zero. For RAID arrays it is usually the stripe width or the internal track size.”raid-chunk-size” is 1mb and there are 7 data disks + 2 parity disk in both of my raids.. so I think that value is actually correct?
I don’t have any way to format the NVME disks back to 512b LBA and test them… giving that ability via the command line would be nice.
nvme format /dev/nvme0n1 --lbaf=0 on the cli or similar would be nice.
Right now. I have a very expensive paperweight until I find a solution.
If anybody has a ROSE and a few spare disks.. please feel free to test LBA 512 vs 4k for me.