I have a conceptual question regarding WireGuard in a multi-WAN environment using dynamic addresses.
Problem: in ROS, when a passive WireGuard peer receives its initial handshake (i.e., when connection-state = new), the state machine doesn’t keep track of either the destination address or the inbound interface. Consequently, the peer sends its handshake reply through the default gateway which breaks functionality in a multi-WAN environment where the ingress and egress addresses must match. This also renders Mangle Connection Marking useless for WireGuard since the handshake must complete before the connection state becomes established.
Question: are there any smarter and cleaner ways to handle policy routing for dynamic WAN addresses, rather than relying on a shaky DHCP script to set the /routing/rule src-address for each interface table?
ps…
EDIT: By shaky, I mean that the script might break if a developer once again and completely unnecessarily decides to change the script compatibility (as someone did with the date format).
Note to myself: ask r&d to add src-interface as a routing rule option.
It is not clear what scenario you are talking about, no diagram?? no config ??
Seriously, what do you mean when a passive peer receives its initial handshake.
What do you mean by passive?
What do you mean by peer?
The wireguard peer ( client for handshake) aggressivelyy sends out a wireguard handshake and its the peer (server for handshake) that receives the in coming traffic.
If you are talking BTH scenario, best handled by someone who uses it.
If talking standard wireguard, this is the exact reason you have mangle rules to ensure traffic to WANX, then leaves the router on WANX, pretty standard fare.
Do you want the input / output version , or the preouting /output version ???
G’day Anav, my sincere apologies if this is a bit to complex for you!
I meant precisely what I wrote: a conceptual question regarding issues with the internal WireGuard handshake process in a multi-WAN environment with no specific scenario in mind.
One challenge with the WireGuard initial handshake is that it occurs in the “new” connection state, ie before connection tracking is established. This means regular connection tracking mechanisms like connection marks won’t help manage inbound/outbound traffic to complete the handshake and setting the connection state to “etablished”. The bottom line is that connection and routing marks are of no use at all when it comes to setting up passive (inbound) multi-WAN WireGuard tunnels.
Also, without policy-based routing all initial WireGuard handshake replies will be sent through the standard default route resulting in a mismatch if it originates from another WAN address (similar to asymmetric routing issues).
Feel free to read my queston again, and then you are more than welcome to return with questions focusing on the handshake process issue and a possible “cleaner” policy routing without scripting, which was my primary objective with the question.
EDIT:
By Passive Peer I mean a WireGuard Peer without a configured endpoint address that will passively wait for an incoming connection.
Perhaps you should use more standard terminology vice the magical language you learn at Santa HQ.
Your question has been answered, its only you that remains in the dark.
I have no problems mangling to ensure Wireguard connections respond appropriately.
As a matter of fact even in a failover situation with two reachable public IPs the aggressive peer will still find the secondary receiving peer as long as one has setup the mangling properly there is no issue.
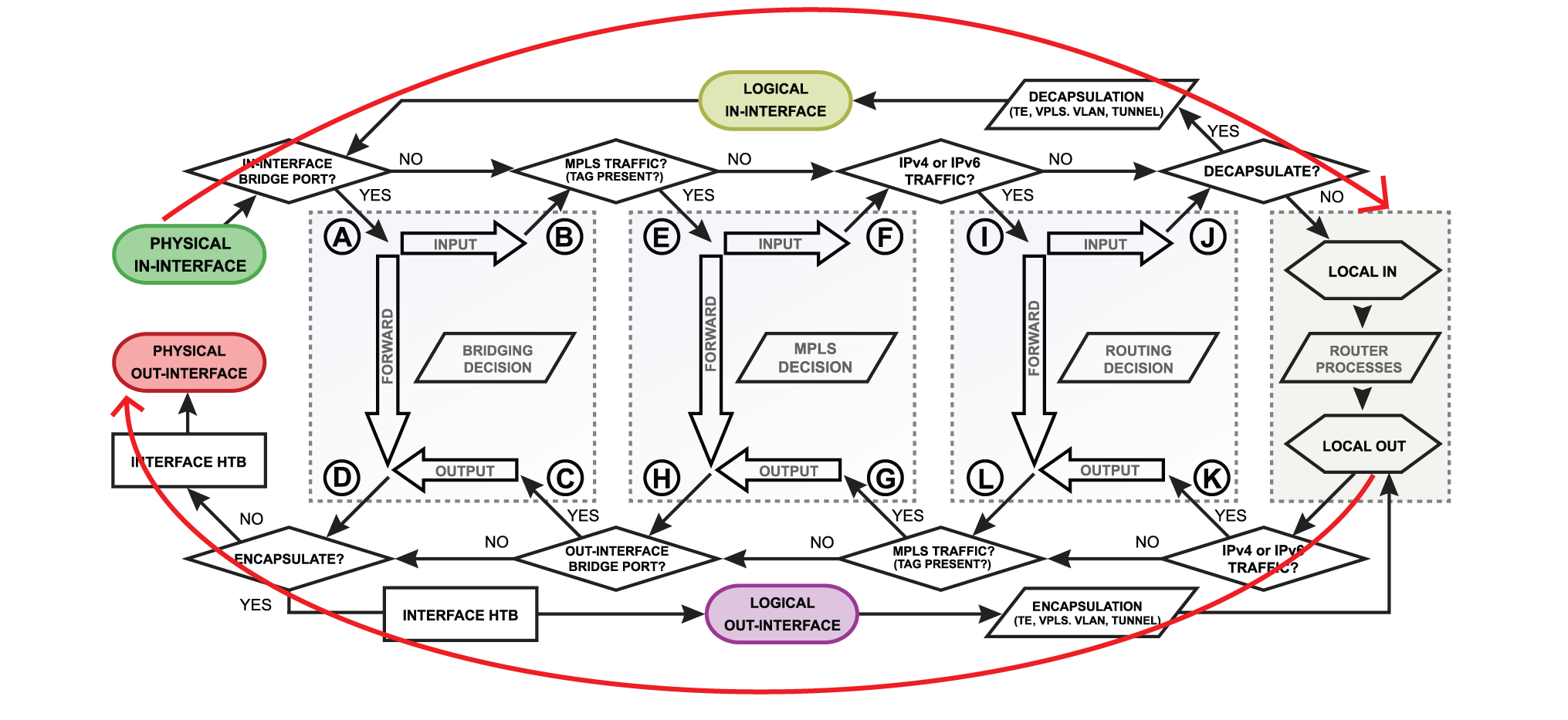
It isn’t that complicated. Here’s a brief illustration of how the issue with WireGuard differs from a built-in service like FTP that works as expected.
Let’s use a couple of examples to show the handshake process flow for two different services on a router equipped with three Internet-facing WAN ports: WAN1 (IP 111), WAN2 (IP 222), and WAN3 (IP 333), where WAN1 is the default gateway.
Example 1 - An FTP client connects to the router’s built-in FTP server using WAN3 (which is working as expected)
The FTP client opens TCP port 21 on WAN3, initiating the TCP handshake (TCP SYN) sent to the input chain. Information about the inbound interface and its associated address is stored internally.
The router sends back a TCP handshake reply (SYN-ACK) to the FTP client using the stored information. This means egress occurs through WAN3 with the source address 333, as intended.
When the TCP handshake process is complete, the connection state is set to ‘established’ by the connection tracker.
Example 2 - A WireGuard client initiates a connection to the router’s WAN3 interface (not working as explected)
A WireGuard client sends a handshake initiation packet to the router’s endpoint (port 15200). This packet is sent down the input chain, and information about the inbound interface and its associated address is stored internally.
The router sends a handshake response packet back to the client. However, the stored information about the inbound interface is not used, meaning the output chain assigns the default gateway (WAN1) as the outbound interface with the egress IP address 111.
The WireGuard client rejects the response packet since the IP address 111 doesn’t match the initiation packet’s IP address 333.
The only way to make the handshake process complete in step 2 above, is to use routing rules to force the routing back to WAN3.
EDIT: This cannot be fixed with connection and route marking because the connection state is still ongoing, i.e. state “new”. The handshake process must first complete with the connection state set to “established” before mangling can be utilized (Catch-22!).
IMO, this design seems flawed. It’s likely caused by a developer mistakenly omitting the interface source address setting.
I’m sorry, but I don’t understand what you mean by “user/group policy” and “User333 belongs to vpn333 group connect to wan333” ?? How does this in any way relate to the asymmetric routing issues that I described earlier in example 2?
Let me just start by stating, that in general, DSTNAT ( normal port forwarding), in your simple case works quite the opposite.
Incoming traffic to a LAN server on WAN3, via DYNDNS URL (or Ip itself) where WAN1 is the primary WAN will fail.
The return traffic will go out WAN1, the original sender will drop the return traffic as the source address on the return is different from the destination address.
In other words, regarding traffic leaving the router, routes prevail!!
Or stated differently, internal connection tracking is for internal purposes NOT for deciding where traffic leaves the router.
Hopefully we have dispelled illusions and myths that you operate within.
I am hesitant to say this is fully the case with your FTP example because it was not clear whether or not you use the FTP ALG and I am unsure of what other side functionality that may or may not include. I tend to think that it should be the same as Ive described above, but its a very edge case I am not as confident about.
The methodology to ensure LAN servers return traffic to the same WAN it came in on is straight forward.:
Wireguard handshake is a completely different animal, in this case the return traffic is NOT coming from LAN servers but from the router itself.
However the same logic applies, if the WG initiates a handshake on WAN3, with WAN1 being primary…then the handshake will fail.
@wfburton, please create a seperate thread if you are not intressed in this specific topic.
@Anav, all that dst-nat, prerouting, and connection marking stuff you posted about is completely irrelevant when it comes to the handshake dilemma. Are you sure you understand where the issue occurs according to example 2?
And as I’ve tried to explain several times earlier, during the initial handshake, the connection and route marking are useless since the handshake process is still ongoing (i.e when connection state is “new”). The handshake process must first complete and then the connection state set to “established” before mangling takes effect (ie no complete handshake, no use of mangling)
In order to facilitate the handshake to complete in a multi-WAN environment (when the inbound interface is not the default gateway) you MUST use policy routing; otherwise the response packet is handed out through the default gateway which makes the handshake fail it the. Okay?
And on top of that, you have to cope with dynamic IP addresses on the WAN interfaces. I’m intrigued by what your “easily fixed” solution will look like.
Well, NO! but let me get back to you with a full trace FYI.
I dare you to set up your own lab environment with just two WAN interfaces and test it yourself. You don’t have to bother using dynamic IP addresses. The task you are to perform is to connect a WireGuard client with a fully functioning connection (handshake ticking) to a WAN interface that is not the default gateway and without policy routing. Then show me that “easy fix”.
Btw, you didn’t answer my question if you understand the root cause as in example 2?
Sorry WB, not a clue why you are showing logs of I dunno what.
As for Larsa,
If I connect to a WAN interface with distance 3, without any other rules setup, there will be no tunnel established.
The only thing that using an improperly configured setup accomplishes is that the peer client will reach the WAN with distance 3, a handsshake will ensue, and then the return traffic will die a quick death. The return traffic will get rejected by the peer client device upon arrival as the source address is not recognized and will be dropped hence no tunnel.
Nothing surprising at all, that just normal routing behaviour and normal responses.
Never throught about this. Same problem in ZeroTier (and IPSec) — the tunnel establishment part get’s tricky through the packet flow diagram. So kinda make sense that WG handshakes are “before new”.
It is a bit unclear. So all works okay today & you’re basically looking for alternatives to a DHCP script. And it’s WAN DHCP clients that do do some update to /routing/rule? And…the underlying concern is your script could break, unexpectedly, if Mikrotik decide to change something in scripting. If so, I share the latter worry & I know scripting pretty well. One wrong/tiny change to how scripting works in future could cause all WANs not to work…
Now I’m not sure of alternatives. Other than potentially worse/complex things, that may not work, generally using some indirect private IPs (recursive routes in reverse, MACVLAN and bridge nat, etc.). I think it be better to “harden” the DHCP script (e.g. handle all error cases, carefully check/convert types e.g. always use a :tostr :toip etc.).
But the DHCP client could use some “built in” things — since scripting something critical like WAN IPs and default routes add more risk than a config setting… e.g. I put a feature request a while back for a “default-check-gateway” option in DHCP client — so you can avoid scripting just to add the check-gateway=ping to the default route. Still waiting…
The secondary issue is exactly how the WG handshake is handled is not cover by Packet Flow diagram:
The WG crypto routing engine is not detailed in the flow diagrams.
THere is no issue with dynamic IPs for WANs, as a persons dyndnsURL will keep the WANIP relevant if it changes and I believe
the crypto routing process will keep the client peer in step with the new WANIP…
Also take a scenario where WAN1 is primary and WAN2 is secondary, and WG tunnel is established via WAN1, and WAN1 drops off line.
The WG process will switch the client peer to WAN2 automatically is my understanding. Also outside the MT flow diagrams.
Built-in Roaming
The client configuration contains an initial endpoint of its single peer (the server), so that it knows where to send encrypted data before it has received encrypted data. The server configuration doesn’t have any initial endpoints of its peers (the clients). This is because the server discovers the endpoint of its peers by examining from where correctly authenticated data originates. If the server itself changes its own endpoint, and sends data to the clients, the clients will discover the new server endpoint and update the configuration just the same. Both client and server send encrypted data to the most recent IP endpoint for which they authentically decrypted data. Thus, there is full IP roaming on both ends.
Note: on flow diagrams, we use output chain to keep WAN traffic within WANs as that is the last step at which to affect change in routing from the router itself.
I think the issue is other side also knows about the 3 WANs – it’s not a smartphone/desktop wanting VPN access. It’s the far-end wants to steer some traffic down a particular WAN(s), that may not be the “primary”*. I don’t think DDNS/etc solve this issue — somehow the dynamic public IP address needs to make it into a /routing/rule. And /routing/rule is based on IP/subnet without any address-list or interface-list support… so options are limited.
Perhaps an example: have some VPS with CHR, and that’s where these 3 WAN WG tunnels go to then route from VPS. Then say you want to manually use one of the non-primary WG tunnels for management from VPS to the 3xWAN-Mikrotik. And it’s there where you need the policy rules – you need to match the dst-address, to put the heartbeat in the right routing table to go back to same one it came in on.
@Larsa, even if theoretically, some diagram of topology would help here. If there is some better solution … a picture may help find it.
*FWIW, you’d have an even worse problem with ECMP routes, than three WANs with different distances case, since it be random which one it uses. Updating /routing/rule based WAN dst-address does fix both, bu
@Anav, unfortunately you’re still missing the point but Ammo seems to grasp it.
In short, ROS connection tracker mishandles WireGuard handshakes. It forces response packets through the default gateway, breaking the protocol if the initial handshake came from a different interface. See Example 2 for reference.
ROS connection tracker, which monitors inbound interfaces and addresses, is based on standard Linux functionality customized by the Mikrotik developers using features like connection tracker “helpers” and “hooks”. On a regular linux machine, this can be accomplished using flexible configuration files but since ROS is locked there are no other alternatives than using separate routing policys for each and every WAN interface.
Well, on Linux, WireGuard also makes heavy use of scripts and routing rules. If you look at the bash script for wg-quick, maybe the DHCP rule doesn’t look so bad.
Perhaps there is bug here… in RouterOS, @anav’s logic should hold true for a tunnel/interface. But WG needing /routing/rule on RouterOS is not surprising either… since that’s how it works on Linux (e.g. you do not use the firewall/conntrack/etc to configure WG).